
 Looker Studio
Looker Studio 
V2A Voice to Audio est la nouvelle IA lancée par Google DeepMind
Au cours de la conférence Google I/O 2024, Google a dévoilé VEO, un modèle text-to-video, bien que les vidéos produites par ce modèle manquent de son. DeepMind s’efforce de remédier à cette lacune et a […]

Ce que vous allez découvrir
- Qu’est-ce que c’est ?
- Comprendre la génération
- Pas encore au point dans certain cas
- Conclusion
V2A Voice to Audio est la nouvelle IA lancée par Google DeepMind

Au cours de la conférence Google I/O 2024, Google a dévoilé VEO, un modèle text-to-video, bien que les vidéos produites par ce modèle manquent de son. DeepMind s’efforce de remédier à cette lacune et a récemment présenté les progrès de sa technologie vidéo-audio (V2A), qui intègre des pixels vidéo et des instructions textuelles pour créer des bandes sonores synchronisées.

Qu’est-ce que c’est ?
Le modèle V2A peut être utilisé avec des modèles de génération vidéo comme VEO pour créer des effets sonores, de la musique et des dialogues adaptés à chaque scène. Il peut également ajouter des bandes sonores à diverses séquences, telles que des films muets, des documents d’archives, et plus encore, élargissant ainsi les possibilités créatives.
V2A permet aux utilisateurs de contrôler précisément la sortie audio. Les créateurs peuvent orienter la génération sonore vers des sons spécifiques ou éviter ceux qui ne conviennent pas. Cette flexibilité facilite l’expérimentation rapide de différentes options audio, permettant de choisir la meilleure correspondance pour chaque vidéo.
Voici quelques exemples de vidéos dont le son a été ajouté par V2A avec les prompt pour chacun :
Comprendre la génération
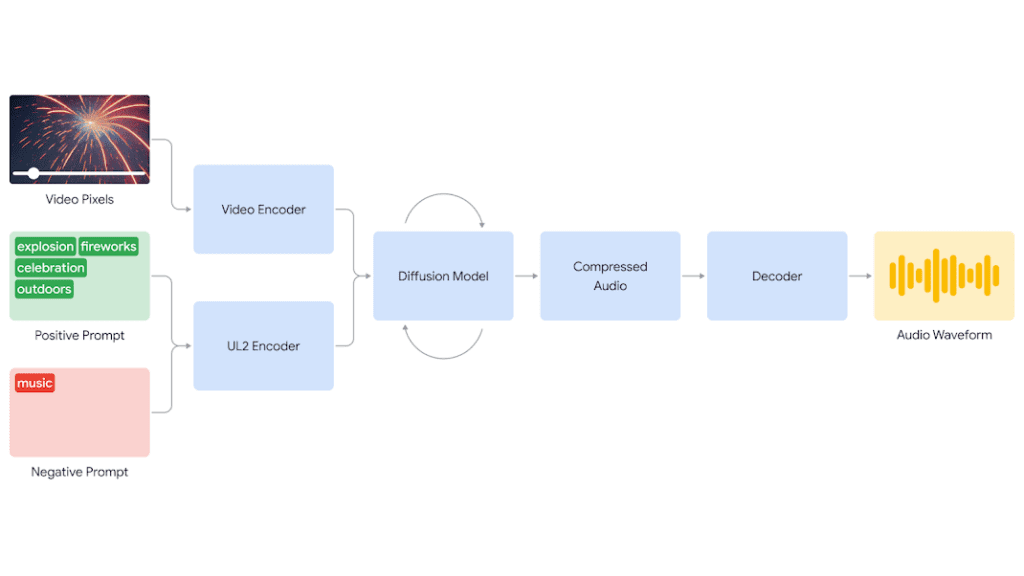
Le système V2A commence par encoder la vidéo d’entrée dans une représentation compressée. Ensuite, un modèle de diffusion affine progressivement l’audio à partir de bruit aléatoire, guidé par les pixels vidéo et les instructions textuelles. Finalement, l’audio généré est décodé en une forme d’onde et synchronisé avec la vidéo.
Pour améliorer la qualité et la pertinence des sons produits, V2A utilise des annotations et des transcriptions détaillées lors de son entraînement. Cette méthode permet au système d’apprendre à associer des événements audio spécifiques à diverses scènes visuelles, assurant ainsi une synchronisation audio-vidéo convaincante.
Pas encore au point dans certain cas
En plus de la musique et des bruits de fond, la nouvelle IA de Google peut même générer des voix, comme illustré dans la vidéo ci-dessous. Cependant, Google reconnaît que son modèle rencontre encore des difficultés à synchroniser les dialogues avec les vidéos. « V2A tente de générer de la parole à partir des transcriptions d’entrée et de la synchroniser avec les mouvements des lèvres des personnages. Cependant, le modèle de génération de vidéos associé ne peut pas être conditionné par les transcriptions. Cela crée un décalage, entraînant souvent une synchronisation labiale imparfaite, car le modèle vidéo ne produit pas de mouvements de bouche correspondant à la transcription, » explique l’entreprise.
Conclusion
Google estime que V2A se distingue des autres modèles de génération d’audio existant : l’IA est capable de comprendre “les pixels bruts” et les prompts sous forme de texte ne sont qu’une option. Sinon, pour la façon dont cette IA a été développée, Google explique qu’il a entraîné le modèle avec des vidéos, de l’audio, et des annotations, afin que V2A comprenne quels sons correspondent à un événement visuel donné.
Concernant la disponibilité de cette technologie, la firme explique qu’elle va d’abord réaliser des évaluations et des tests, avant d’envisager de rendre V2A accessible au public.
C’est la fin de cet article ! Si vous souhaitez avoir plus d’informations sur les outils Google et sur l’IA, restez connectés pour en savoir plus !
Si vous souhaitez développer un projet avec notre équipe de développeurs de choc, contactez-nous via ce formulaire.
Numericoach dispose d’une offre packagée pour les licences Google Workspace, unique en France.
À bientôt !
- Articles connexes
- Plus de l'auteur



News
NotebookLM est désormais disponible en tant que service supplémentaire
L'année dernière, Google a lancé une application d'accès anticipé appelée NotebookLM, un produit expérimental utilisant certains des modèles les plus avancés de Google, comme Gemini 1.5 Pro, qui vous aide à obtenir ...
1 min
![]() Thierry Vanoffe 11 mois
Thierry Vanoffe 11 mois




Développeur Google Apps Script
