
 Looker Studio
Looker Studio 
L’ère de la raison maîtrisée : plongez au cœur de Gemini 2.5 Flash
Le paysage de l’intelligence artificielle générative évolue à une vitesse vertigineuse. Chaque annonce, chaque nouveau modèle repousse les limites de ce que l’on croyait possible, ouvrant des perspectives inédites pour les développeurs, les entreprises et, […]

Ce que vous allez découvrir
- Le raisonnement au cœur de l'innovation : qu'est-ce qu'un modèle de réflexion ?
- Gemini 2.5 Flash : L'hybride parfait entre vitesse, coût et intelligence
- Commencer à construire aujourd'hui : accès et perspectives
- Anecdotes et réflexions personnelles
- Conclusion
L’ère de la raison maîtrisée : plongez au cœur de Gemini 2.5 Flash

Le paysage de l’intelligence artificielle générative évolue à une vitesse vertigineuse. Chaque annonce, chaque nouveau modèle repousse les limites de ce que l’on croyait possible, ouvrant des perspectives inédites pour les développeurs, les entreprises et, in fine, pour nous tous. Au milieu de cette effervescence, une nouveauté retient particulièrement l’attention, non seulement par ses performances, mais aussi par la philosophie qui la sous-tend : l’arrivée de Gemini 2.5 Flash, désormais accessible en version préliminaire via l’API Gemini sur Google AI Studio et Vertex AI.
Plus qu’une simple itération, Gemini 2.5 Flash marque un tournant. S’appuyant sur les solides fondations de son prédécesseur, Flash 2.0, cette nouvelle version introduit une amélioration majeure et fascinante : la capacité de raisonnement contrôlable. Imaginez un modèle capable non seulement de générer du texte, mais aussi de « réfléchir », de décomposer des problèmes complexes, de planifier avant de répondre. C’est précisément ce que propose Gemini 2.5 Flash, et c’est une avancée qui change la donne pour de nombreux cas d’utilisation.
Mais ce qui rend Gemini 2.5 Flash véritablement unique, c’est la mainmise qu’il offre aux développeurs sur ce processus de réflexion. Fini le raisonnement en « boîte noire ». Ici, vous décidez si le modèle doit réfléchir, et surtout, combien de « budget » de réflexion vous lui allouez. Cette flexibilité est un atout considérable dans un monde où chaque milliseconde de latence et chaque centime comptent.
Nous allons explorer ensemble les subtilités de Gemini 2.5 Flash, comprendre ce que signifie réellement un modèle de « raisonnement hybride », découvrir comment maîtriser le « budget de réflexion » pour optimiser la qualité, le coût et la latence, et envisager les innombrables possibilités qu’offre cette nouvelle ère de l’IA contrôlable. Préparez-vous à plonger au cœur d’une technologie qui s’annonce déjà comme un pilier de l’innovation à venir.
Le raisonnement au cœur de l’innovation : qu’est-ce qu’un modèle de réflexion ?
Pour saisir toute la portée de Gemini 2.5 Flash, il est essentiel de comprendre le concept de « modèle de raisonnement ». Traditionnellement, de nombreux modèles génératifs fonctionnent de manière relativement directe : ils reçoivent une invite, la traitent et génèrent une réponse quasi instantanément, basée sur les schémas et les informations qu’ils ont appris lors de leur entraînement. Cela fonctionne très bien pour de nombreuses tâches, mais montre ses limites face à des problèmes nécessitant une analyse plus poussée, une décomposition en étapes, ou une planification.
Un modèle de raisonnement, comme les modèles Gemini 2.5, aborde l’invite différemment. Avant de produire une sortie, il peut engager un processus interne que Google décrit comme de la « réflexion ». Imaginez cela comme une phase de délibération interne. Le modèle ne se contente pas de réagir, il réfléchit.
Cette « réflexion » peut prendre plusieurs formes. Il peut s’agir de reformuler l’invite pour mieux la comprendre, de décomposer une tâche complexe en sous-tâches plus gérables, d’explorer différentes approches pour résoudre un problème, ou encore de planifier la structure et le contenu de sa réponse. C’est un peu comme un être humain qui, face à une question difficile, ne répond pas du tac au tac, mais prend un moment pour y penser, organiser ses idées, et structurer sa réponse.
Les avantages de cette approche sont multiples et significatifs. Pour les tâches complexes qui exigent plusieurs étapes de logique ou une compréhension nuancée, la capacité de raisonnement permet au modèle d’atteindre une précision et une pertinence bien supérieures. Pensez à la résolution de problèmes mathématiques ardus, à l’analyse de documents complexes, ou à la génération de code sophistiqué. Dans ces scénarios, un modèle capable de « réfléchir » étape par étape a de bien meilleures chances d’arriver à la bonne solution qu’un modèle qui se contente de générer une réponse basée sur des corrélations statistiques.
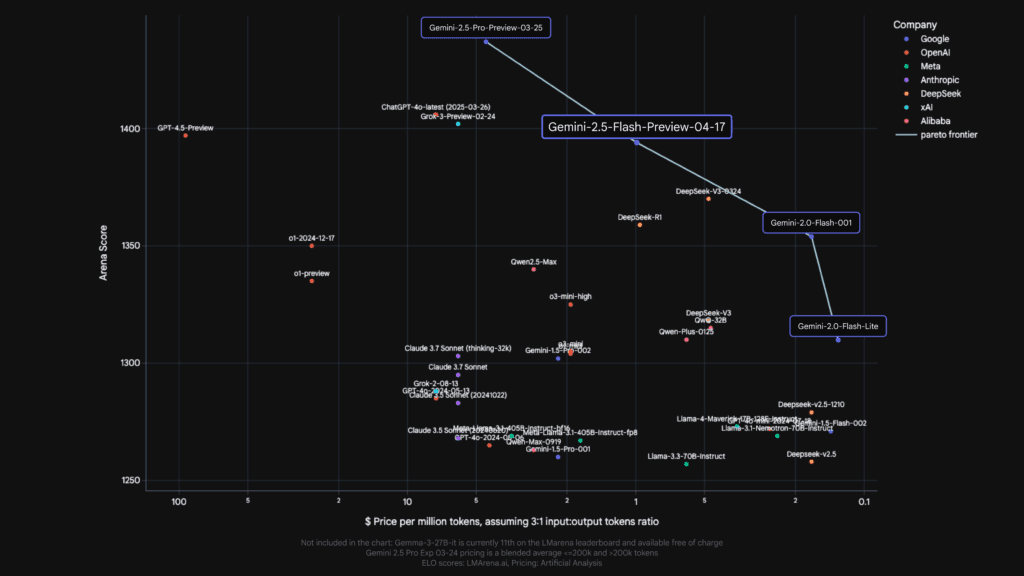
Google illustre cette capacité en mentionnant les excellents résultats de Gemini 2.5 Flash sur les invites difficiles dans LMArena, ne étant devancé que par son grand frère, Gemini 2.5 Pro. C’est un témoignage éloquent de l’efficacité du raisonnement intégré dans ce modèle.
Gemini 2.5 Flash : L’hybride parfait entre vitesse, coût et intelligence
Là où Gemini 2.5 Flash innove véritablement, c’est dans sa nature de « modèle de raisonnement entièrement hybride ». Qu’est-ce que cela signifie concrètement ? Cela signifie que le raisonnement n’est pas une fonctionnalité monolithique, toujours activée ou désactivée. Au lieu de cela, les développeurs ont la capacité de l’activer ou de le désactiver à leur guise, et surtout, de le doser avec précision.
Avant Flash 2.5, on pouvait imaginer un choix binaire : soit on utilisait un modèle rapide et économique mais moins « intelligent » pour les tâches simples, soit un modèle plus puissant et raisonnant pour les tâches complexes, mais potentiellement plus lent et coûteux. Gemini 2.5 Flash vient briser ce dilemme en offrant le meilleur des deux mondes.
La clé de cette hybridation réside dans le concept de « budget de réflexion ». C’est un paramètre novateur qui permet aux développeurs de définir la quantité maximale de jetons que le modèle peut utiliser pour son processus de raisonnement interne. C’est comme donner au modèle un certain temps ou une certaine quantité de « matière grise » à dépenser avant de générer sa réponse finale.
Un budget de réflexion plus élevé donne au modèle plus de latitude pour explorer différentes pistes, décomposer le problème plus finement, et planifier sa réponse de manière plus approfondie. Naturellement, cela peut potentiellement améliorer la qualité et la précision de la sortie, surtout pour des invites particulièrement complexes. Cependant, un budget de réflexion plus élevé peut également entraîner une latence légèrement supérieure et un coût proportionnel à la quantité de jetons utilisés pour la réflexion.
Et c’est là toute la beauté de l’approche hybride de Gemini 2.5 Flash : elle offre un contrôle granulaire. Les développeurs ne sont pas contraints par un comportement prédéfini. Ils peuvent ajuster le budget de réflexion pour trouver le point d’équilibre parfait entre la qualité souhaitée, les contraintes de latence de leur application et les impératifs de coût.
Imaginez un cas d’utilisation où la rapidité est primordiale, comme un chatbot conversationnel répondant à des questions simples. Dans ce scénario, un budget de réflexion faible, voire nul (nous y reviendrons), permet de garantir des réponses quasi instantanées, similaires à la vitesse de Flash 2.0, tout en bénéficiant potentiellement des améliorations de performance intrinsèques de Gemini 2.5 Flash même sans raisonnement activé au maximum.
À l’inverse, pour une application nécessitant une analyse de données complexe ou la génération de contenu technique précis, un budget de réflexion plus conséquent peut être alloué, permettant au modèle d’utiliser pleinement ses capacités de raisonnement pour fournir une réponse de haute qualité, même si cela implique une légère augmentation de la latence.
Cette capacité à moduler le raisonnement fait de Gemini 2.5 Flash un outil incroyablement polyvalent, capable de s’adapter à une large gamme de cas d’utilisation, des plus simples aux plus exigeants.
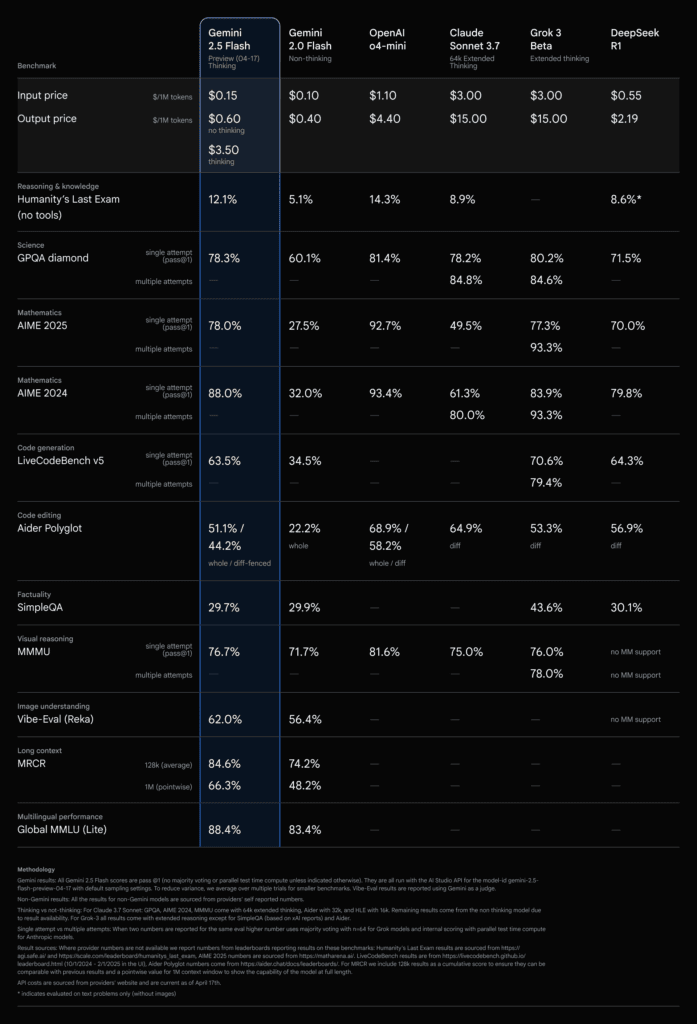
Le modèle de réflexion leplus rentable : l’équation économique de Gemini 2.5 Flash
Dans le monde de l’IA générative, la performance ne se mesure pas uniquement à la qualité des sorties ou à la rapidité. Le coût est un facteur déterminant, en particulier pour les applications à grande échelle. C’est dans ce domaine que Gemini 2.5 Flash se distingue particulièrement, s’affirmant comme le modèle de raisonnement le plus rentable disponible à ce jour.
Pourquoi cette rentabilité ? Plusieurs facteurs y contribuent. Tout d’abord, en offrant un contrôle précis sur le budget de réflexion, Gemini 2.5 Flash permet aux développeurs de ne « payer » que pour le raisonnement dont ils ont réellement besoin. Si une invite est simple et ne nécessite qu’une analyse minimale, le modèle utilisera peu ou pas de jetons pour la réflexion, maintenant ainsi un coût bas. C’est un contraste marqué avec des modèles où le raisonnement est un processus opaque et potentiellement coûteux, même pour des tâches triviales.
Ensuite, même avec un budget de réflexion de 0, Gemini 2.5 Flash bénéficie des optimisations et des améliorations apportées à l’architecture de base des modèles Gemini 2.5. Cela signifie que même sans activer le raisonnement interne, les développeurs peuvent constater une amélioration des performances par rapport à Flash 2.0, tout en conservant les vitesses élevées et le coût abordable qui caractérisaient la version précédente. C’est comme obtenir une mise à niveau gratuite de performance sans coût supplémentaire.
Le concept de « budget de réflexion » agit donc non seulement comme un levier de qualité et de latence, mais aussi comme un puissant outil de gestion des coûts. Les développeurs peuvent finement calibrer leurs dépenses en fonction des exigences spécifiques de chaque requête ou de chaque type de tâche. Pour des millions de requêtes traitées quotidiennement, cette granularité dans la gestion des coûts peut représenter des économies substantielles.
Prenons un exemple concret. Imaginez une application qui utilise l’IA pour générer des descriptions de produits. Pour des produits standards avec des caractéristiques simples, un budget de réflexion nul ou très faible peut être suffisant, garantissant une génération rapide et économique. Pour des produits plus complexes nécessitant une analyse de spécifications techniques ou une mise en contexte particulière, un budget de réflexion plus élevé peut être alloué pour garantir des descriptions précises et convaincantes. Cette flexibilité permet d’optimiser l’utilisation des ressources et de maîtriser les dépenses.
Google positionne clairement Gemini 2.5 Flash comme le « modèle offrant le meilleur rapport qualité-prix ». C’est un message fort qui résonne auprès des développeurs et des entreprises soucieux d’optimiser leurs investissements dans l’IA sans sacrifier la performance. La capacité à bénéficier d’un raisonnement puissant tout en gardant un œil vigilant sur les coûts fait de Gemini 2.5 Flash une option extrêmement attrayante pour une large gamme d’applications.
Des contrôles précis pour une maîtrise totale : le budget de réflexion expliqué
Le budget de réflexion est sans aucun doute l’une des fonctionnalités les plus intéressantes de Gemini 2.5 Flash. Il incarne cette volonté de Google de donner aux développeurs les outils nécessaires pour sculpter le comportement du modèle en fonction de leurs besoins précis. Ne vous y trompez pas, il ne s’agit pas d’un simple interrupteur on/off, mais d’une véritable manette de contrôle offrant une granularité impressionnante.
Comme mentionné précédemment, le budget de réflexion définit le nombre maximal de jetons que le modèle est autorisé à consommer pendant sa phase de raisonnement interne. Ce budget peut être ajusté via l’API Gemini ou via l’interface intuitive de Google AI Studio et Vertex AI. C’est une flexibilité bienvenue qui permet aux développeurs de tester et d’expérimenter pour trouver le réglage optimal pour chaque cas d’utilisation.
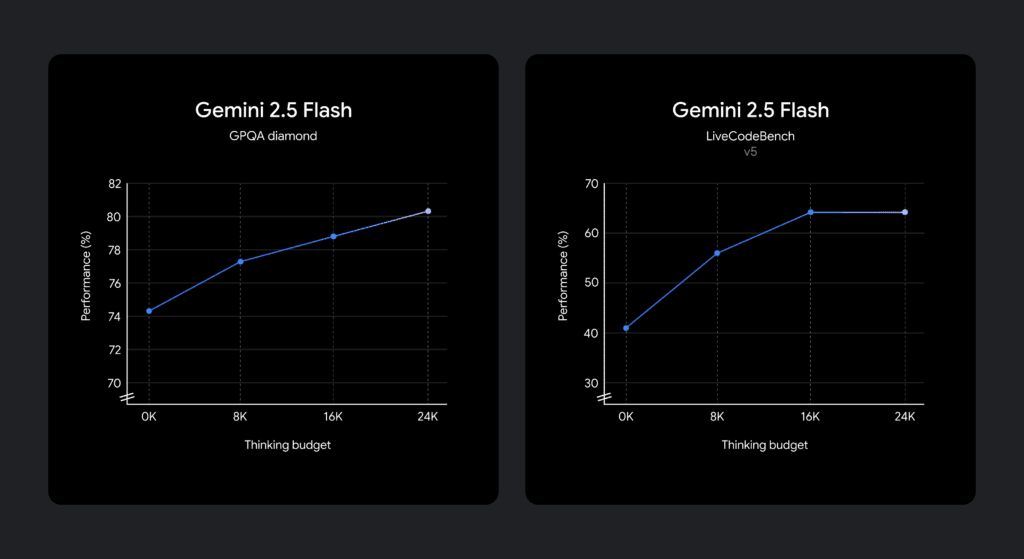
La plage de réglage de ce budget est impressionnante, allant de 0 à 24 576 jetons pour Flash 2.5. Cette large amplitude permet de couvrir un spectre très large de besoins, depuis les tâches ne nécessitant aucune réflexion explicite jusqu’à celles qui bénéficieraient d’une analyse approfondie.
Un point crucial à comprendre est que le budget de réflexion ne contraint pas le modèle à utiliser la totalité des jetons alloués. Le modèle est intelligent. Il est entraîné pour évaluer la complexité d’une invite et décider, en fonction de cette complexité et du budget disponible, de la quantité de raisonnement nécessaire. Si une invite est simple, le modèle utilisera très peu, voire aucun, jeton de réflexion, même si un budget important lui a été alloué. Cela garantit une efficacité maximale et évite de consommer inutilement des ressources.
C’est un mécanisme sophistiqué : le modèle évalue la tâche, détermine le niveau de raisonnement qu’elle requiert, et utilise ensuite le budget alloué de manière optimale, sans nécessairement l’épuiser. Cela ajoute une couche d’intelligence autonome à la fonctionnalité de contrôle manuel du budget.
Comment utiliser concrètement ce budget de réflexion ? Google propose des orientations claires. Si l’objectif principal est de minimiser le coût et la latence tout en obtenant des performances supérieures à Flash 2.0, la consigne est simple : définissez le budget de réflexion sur 0. Dans ce mode, le modèle se comportera de manière très similaire à Flash 2.0 en termes de rapidité et de coût, tout en bénéficiant des améliorations sous-jacentes de l’architecture Gemini 2.5.
Si, en revanche, la qualité de la réponse est primordiale pour des invites complexes, augmenter progressivement le budget de réflexion est la voie à suivre. En expérimentant avec différentes valeurs, les développeurs peuvent observer l’impact sur la qualité de la sortie, la latence et le coût, et trouver le point d’équilibre idéal pour leur application. Le processus est itératif et encourage l’optimisation.
L’accès à ce paramètre via l’API et les interfaces graphiques rend cette expérimentation accessible à tous les niveaux de développeurs, des débutants aux experts. C’est une invitation à la personnalisation et à l’optimisation, permettant de tirer le meilleur parti de Gemini 2.5 Flash pour chaque besoin spécifique. Les invites d’exemple fournies par Google démontrent la manière dont le raisonnement peut être activé et utilisé par défaut dans le mode standard de Flash 2.5, mais le véritable pouvoir réside dans la capacité à moduler ce comportement.
Commencer à construire aujourd’hui : accès et perspectives
La bonne nouvelle pour les développeurs et les entreprises désireuses d’explorer les capacités de Gemini 2.5 Flash est qu’il est d’ores et déjà accessible. Cette version préliminaire est disponible via les canaux habituels de Google pour l’accès aux modèles d’IA : l’API Gemini, Google AI Studio et Vertex AI. De plus, il est également intégré dans une liste déroulante dédiée au sein de l’application Gemini, rendant son utilisation encore plus simple pour ceux qui préfèrent une interface utilisateur.
Cette disponibilité précoce est un signal fort de Google. Cela montre la confiance dans la maturité du modèle et la volonté de mettre rapidement cette technologie innovante entre les mains de la communauté des développeurs pour qu’ils puissent commencer à construire et à expérimenter. L’accès via l’API est essentiel pour l’intégration de Gemini 2.5 Flash dans des applications existantes ou la création de nouvelles solutions personnalisées. Google AI Studio offre un environnement convivial pour prototyper et tester rapidement des idées sans avoir à écrire beaucoup de code, tandis que Vertex AI fournit une plateforme d’entreprise robuste pour déployer et gérer des applications IA à grande échelle.
L’intégration dans l’application Gemini elle-même suggère également une volonté de démocratiser l’accès à ces capacités de raisonnement, potentiellement pour des usages plus généraux ou exploratoires.
L’encouragement de Google à « expérimenter avec ce thinking_budget paramètre » n’est pas anodin. C’est une invitation directe à plonger dans les détails, à tester l’impact de différentes valeurs sur les performances, la latence et les coûts pour des cas d’utilisation spécifiques. C’est par cette expérimentation que les développeurs découvriront le potentiel réel de Gemini 2.5 Flash et comment le raisonnement contrôlable peut les aider à relever des défis qu’ils ne pouvaient peut-être pas aborder efficacement auparavant.
depuis Google importer genai
client = genai . Client ( api_key = "GEMINI_API_KEY" )
response = client . models . generate_content (
model = "gemini-2.5-flash-preview-04-17" ,
contents = "Vous lancez deux dés. Quelle est la probabilité qu'ils totalisent 7 ?" ,
config = genai . types . GenerateContentConfig (
thinking_config = genai . types . ThinkingConfig (
thinking_budget = 1024
)
)
)
imprimer ( réponse . texte )Quelles sont les perspectives offertes par Gemini 2.5 Flash et sa capacité de raisonnement contrôlable ? Elles sont vastes et touchent de nombreux secteurs. Dans le domaine du développement logiciel, on peut imaginer une assistance à la programmation plus intelligente, capable de comprendre le contexte d’un projet complexe et de proposer des solutions de code plus pertinentes. Dans le service client, des chatbots capables de mieux analyser les requêtes complexes des utilisateurs avant de fournir une réponse détaillée. Dans l’éducation, des outils d’apprentissage personnalisés capables d’adapter leur approche en fonction de la manière dont un élève résout un problème. Dans la création de contenu, une assistance capable de proposer des structures narratives plus sophistiquées ou d’analyser des sources multiples pour synthétiser des informations complexes.
La capacité à doser le raisonnement permet également de concevoir des architectures d’applications plus intelligentes et plus efficaces. On peut imaginer des systèmes qui utilisent un budget de réflexion faible pour les requêtes courantes afin de garantir une réponse rapide, et qui augmentent dynamiquement ce budget pour les requêtes plus rares ou plus complexes nécessitant une analyse approfondie. Cette flexibilité est un atout majeur pour construire des systèmes réactifs et économiques.
L’arrivée de Gemini 2.5 Flash marque une étape importante dans l’évolution des modèles d’IA. Elle ne se contente pas d’améliorer les performances brutes, elle introduit un niveau de contrôle et de flexibilité qui était jusqu’à présent largement absent. C’est une technologie qui invite à l’expérimentation, à l’innovation et à la création de solutions IA plus intelligentes, plus efficaces et plus adaptées aux besoins spécifiques de chaque utilisateur ou application. Le futur de l’IA générative passe par une meilleure compréhension et une meilleure maîtrise des processus internes des modèles, et Gemini 2.5 Flash ouvre la voie dans cette direction.
Anecdotes et réflexions personnelles
Il est fascinant d’observer la rapidité avec laquelle ces modèles d’IA évoluent. Il y a encore peu de temps, la capacité à générer du texte cohérent semblait déjà une prouesse. Aujourd’hui, nous parlons de modèles capables de « réfléchir » et dont on peut même ajuster le « budget de pensée ». C’est un rappel constant que nous ne sommes qu’au début de cette révolution de l’IA.
J’ai eu l’occasion d’expérimenter avec différentes versions de modèles linguistiques au fil du temps, et l’une des frustrations récurrentes était le manque de transparence dans la manière dont les réponses étaient générées. On envoyait une invite, et on obtenait une réponse, sans comprendre réellement le cheminement qui y avait mené. L’idée d’un « budget de réflexion » qui rend ce processus plus visible, plus contrôlable, est particulièrement excitante. C’est comme si l’on passait d’une « boîte noire » à une « boîte grise », où l’on peut entrevoir, et même influencer, les processus internes du modèle.
Cette capacité de contrôle fin me fait penser à la manière dont les développeurs ont historiquement optimisé les algorithmes. On ne se contente pas d’utiliser une fonction générique ; on cherche à comprendre son fonctionnement interne pour l’adapter au mieux au problème spécifique que l’on cherche à résoudre. Le « budget de réflexion » de Gemini 2.5 Flash offre une opportunité similaire dans le domaine de l’IA générative. C’est une invitation à devenir un « chef d’orchestre » de l’IA, capable de moduler son comportement pour en tirer la quintessence.
L’aspect économique est également crucial. Dans un contexte professionnel, chaque euro compte. Savoir que l’on peut ajuster le coût de la « pensée » du modèle en fonction de la valeur apportée par cette pensée pour une tâche donnée est un argument de poids. Cela ouvre la porte à une utilisation plus efficiente et plus rentable de l’IA, permettant potentiellement d’intégrer des capacités de raisonnement même dans des applications où le coût était auparavant un frein majeur.
Je suis particulièrement curieux de voir les cas d’utilisation créatifs que les développeurs vont inventer grâce à cette fonctionnalité. Comment ce contrôle sur le raisonnement va-t-il transformer la manière dont nous interagissons avec l’IA ? Quelles nouvelles applications vont émerger qui exploitent pleinement cette capacité à doser l’intelligence ? Les possibilités semblent infinies.
Il est clair que l’approche de Google avec Gemini 2.5 Flash est axée sur l’autonomisation des développeurs. Ils ne fournissent pas seulement un modèle puissant, ils offrent également les outils nécessaires pour l’adapter finement aux besoins spécifiques. C’est une approche qui, je pense, va accélérer l’innovation et permettre la création de solutions IA plus intelligentes, plus performantes et plus adaptées aux réalités du monde réel. Le futur de l’IA ne se résume pas à la création de modèles toujours plus grands ; il réside aussi dans la capacité à maîtriser et à optimiser les modèles existants, et c’est précisément ce que permet Gemini 2.5 Flash.
C’est une période passionnante pour être impliqué dans le domaine de l’IA. Chaque nouvelle annonce apporte son lot de surprises et ouvre de nouvelles voies. Gemini 2.5 Flash, avec son concept de raisonnement contrôlable, est sans aucun doute l’une des avancées les plus significatives de ces derniers mois. C’est une technologie qui mérite d’être explorée en profondeur, expérimentée sans relâche, et qui a le potentiel de transformer la manière dont nous construisons avec l’intelligence artificielle.
Conclusion
L’arrivée de Gemini 2.5 Flash marque une étape significative dans l’évolution des modèles d’intelligence artificielle générative. En introduisant la capacité de raisonnement contrôlable, Google ne se contente pas de proposer un modèle plus performant ; il offre aux développeurs un niveau de maîtrise inédit sur le comportement de l’IA.
Cette nature de « modèle de raisonnement entièrement hybride », combinée au concept novateur de « budget de réflexion », permet un ajustement fin entre la qualité, le coût et la latence, ouvrant ainsi la porte à une multitude de cas d’utilisation, des plus simples aux plus complexes. Que l’on souhaite privilégier la vitesse et l’économie ou la profondeur de l’analyse, Gemini 2.5 Flash offre la flexibilité nécessaire pour trouver le point d’équilibre parfait.
Son positionnement comme le modèle de raisonnement le plus rentable du marché, même avec un budget de réflexion nul, en fait une option particulièrement attractive pour les entreprises soucieuses d’optimiser leurs investissements dans l’IA. L’accès simplifié via l’API Gemini, Google AI Studio et Vertex AI encourage l’expérimentation et l’intégration rapide dans les flux de travail existants.
En donnant aux développeurs les outils nécessaires pour moduler la « pensée » du modèle, Google ouvre la voie à une nouvelle génération d’applications IA, plus intelligentes, plus efficaces et mieux adaptées aux besoins spécifiques. Le thinking_budget n’est pas qu’un simple paramètre ; c’est un levier puissant pour l’innovation.
Si vous êtes un développeur, une entreprise, ou simplement passionné par les avancées de l’IA, nous vous encourageons vivement à explorer Gemini 2.5 Flash. Expérimentez avec son budget de réflexion, testez ses capacités sur vos propres cas d’usage, et découvrez comment cette technologie peut vous aider à résoudre des problèmes complexes de manière plus efficace et plus rentable. L’ère de la raison maîtrisée est là, et les possibilités sont immenses.
Le monde de l’IA évolue à une vitesse folle, et maîtriser ces nouvelles technologies est essentiel pour rester compétitif. Chez Numericoach, nous sommes passionnés par l’accompagnement des professionnels et des entreprises dans leur appropriation de l’intelligence artificielle. Que vous ayez besoin de comprendre les implications de modèles comme Gemini 2.5 Flash pour votre activité, de former vos équipes à l’utilisation des outils IA, ou de développer des solutions sur mesure intégrant ces technologies de pointe, notre expertise est à votre service. Contactez Numericoach dès aujourd’hui pour explorer comment l’IA peut transformer votre potentiel et vous aider à construire l’avenir.
- Articles connexes
- Plus de l'auteur

News
Gemini Deep Think : L’IA qui révolutionne les mathématiques et défie l’impossible !
L'univers des mathématiques, souvent perçu comme un bastion imprenable de la pensée humaine, vient de connaître une révolution silencieuse, mais retentissante. Imaginez un instant : un système d'intelligence artificielle qui ...
7 min
![]() Thierry Vanoffe 2 semaines
Thierry Vanoffe 2 semaines

Gemini au travail : vos données, vos règles
La transformation numérique des entreprises s'accélère, propulsée par des outils toujours plus innovants. Au cœur de cette révolution, l'intelligence artificielle s'impose comme un allié incontournable. Cependant, cette adoption massive soulève ...
4 min
![]() Ahmet Sahin 7 mois
Ahmet Sahin 7 mois


News
Google Meet : enregistrez-vous depuis la salle verte
La participation à des réunions virtuelles, comme sur Google Meet, a radicalement transformé notre manière de communiquer professionnellement, surtout lorsqu'il s'agit de se réunir depuis une salle de conférences. L'un ...
1 min
![]() Thierry Vanoffe 1 an
Thierry Vanoffe 1 an

News
Android : application d’une règle relative aux mots de passe pour les profils professionnels Android avec Google Mobile Management
Nouveauté du 22 mai 2018 : Google Mobile Management permet aux administrateurs G Suite d'offrir aux utilisateurs un accès sécurisé aux applications et aux données de l'entreprise sur leurs appareils mobiles. Pour ...
1 min
![]() Thierry Vanoffe 7 ans
Thierry Vanoffe 7 ans

News
Copiez vos fichiers Google Docs, Sheets et Slides chiffrés côté client
Si le chiffrement côté client est activé pour Google Docs, Sheets et Slides. Vous pouvez désormais faire une copie d'un document, d'une feuille de calcul ou d'une présentation chiffrée existante. Copier des ...
1 min
![]() Thierry Vanoffe 3 ans
Thierry Vanoffe 3 ans
Thierry VANOFFE, consultant, formateur, coach Google Workspace CEO de Numericoach, leader de la formation Google Workspace en France. Passionné par Google, ce blog me permet de partager cette passion et distiller tutos, trucs, astuces, guides sur les outils Google. N'hésitez pas à me solliciter pour vos projets de formation.
