
 Looker Studio
Looker Studio 
Cloud Data Fusion : créer un ETL sur Google Cloud Platform
Que vous fassiez vos premiers pas ou non sur le Cloud et dans l’univers Big Data, il y a certains projets ou cas d’usage pour lesquels vous devez manipuler plusieurs sources de données qui ne […]

Ce que vous allez découvrir
- Prérequis
- Qu’est-ce qu’un ETL ?
- Voici un exemple pour créer votre première instance Data Fusion et commencer un projet ETL
- Félicitations !
Cloud Data Fusion : créer un ETL sur Google Cloud Platform

Que vous fassiez vos premiers pas ou non sur le Cloud et dans l’univers Big Data, il y a certains projets ou cas d’usage pour lesquels vous devez manipuler plusieurs sources de données qui ne sont pas nécessairement dans un format adéquat à leur utilisation finale (analyse des données, visualisation et business intelligence: tableaux de bord et rapports, transfert et migration de données). C’est le cas par exemple quand vous voulez migrer des applications sur site (on-premises) vers le cloud ou quand vous souhaitez enrichir vos données issues d’un CRM avec d’autres sources de données. Dès lors, il est de plus en plus fréquent de faire appel aux outils ETL. Heureusement pour vous tous les outils nécessaires existent sur Google Cloud Platform.
Prérequis
- Posséder un projet Google Cloud Platform (GCP)
Qu’est-ce qu’un ETL ?
Les outils ETL (Extraction-Transformation-Loading=chargement) sont des logiciels ou applications qui ont pour but d’extraire des données depuis plusieurs sources (Extraction), de les nettoyer et de les personnaliser (Transformation) à des fins d’insertion dans des entrepôts de données (Loading). BigQuery est l’entrepôt de données phare de Google Cloud Platform. Pour faire vos premiers pas sur BigQuery je vous recommande cet article Numeriblog.
Les tâches effectuées par un outil ETL
Les tâches effectuées, en fonction de l’entreprise, par le Data Scientist/ Data Analyst/Data Engineer dans le cadre de la démarche ETL sont les suivantes :
- identification des informations pertinentes de la source de données
- extraction de ces informations
- personnalisation et intégration d’autres informations
- nettoyage des données
- alimentation de l’entrepôt de données
Les cas d’usages
Il peut s’agir de consolider une base de données avec des sources de données aux formats différents. Autrement, dans un projet de Machine Learning, retraiter des données afin qu’il soit possible de les incorporer dans un modèle.
Sur Google Cloud Platform
Un outil important utilisé dans GCP est Cloud Data Fusion. L’avantage de ce type d’outil est qu’il n’est pas nécessaire de savoir coder pour arriver à obtenir les résultats souhaités sur vos données. Par exemple, Cloud Data Fusion permet de se connecter à plus de 150 sources de données afin de récupérer les données dans des flux d’intégration (Extraction), à travers son interface no-code. Un autre outil développé par Trifacta, Dataprep, permet l’import, le nettoyage et plus globalement la préparation de données pour des modèles de Machine Learning.
Voici un exemple pour créer votre première instance Data Fusion et commencer un projet ETL
Vous allez appliquer le schéma suivant :
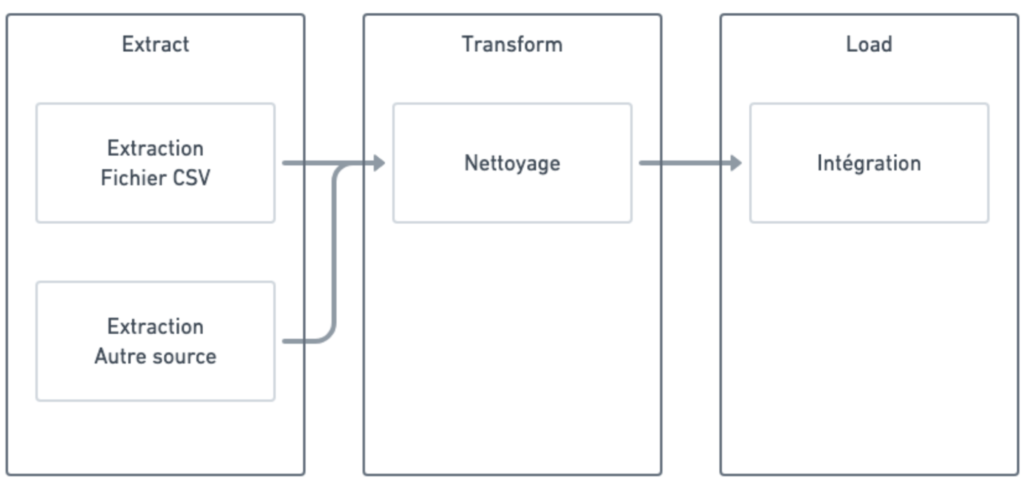
Configuration de l’instance Data Fusion
Vous allez dans un premier temps créer une instance Data Fusion. Celle-ci sera un déploiement unique et séparé d’autres instances Data Fusion de votre projet GCP.
Commencez par chercher et sélectionnez Data Fusion dans la barre de recherche de Google Cloud Platform.
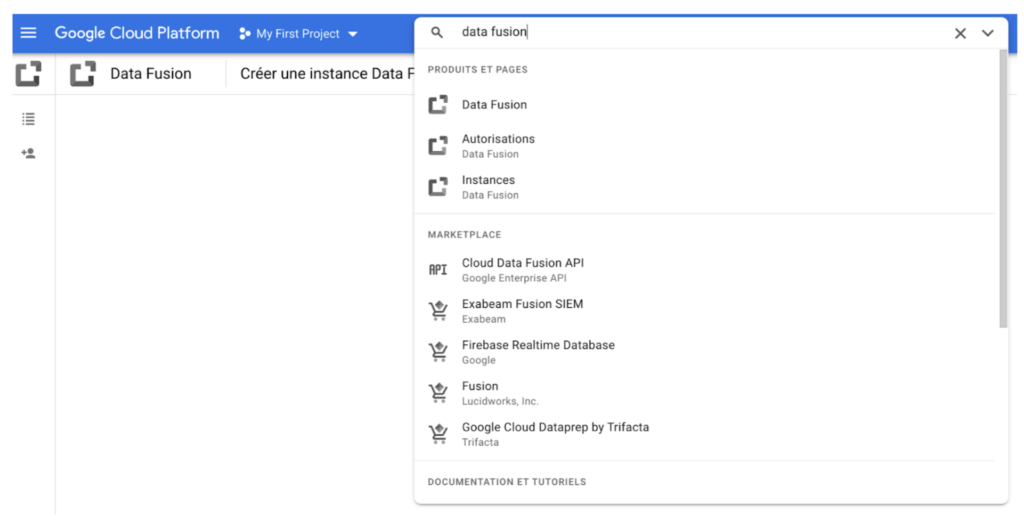
Puis créez une instance.
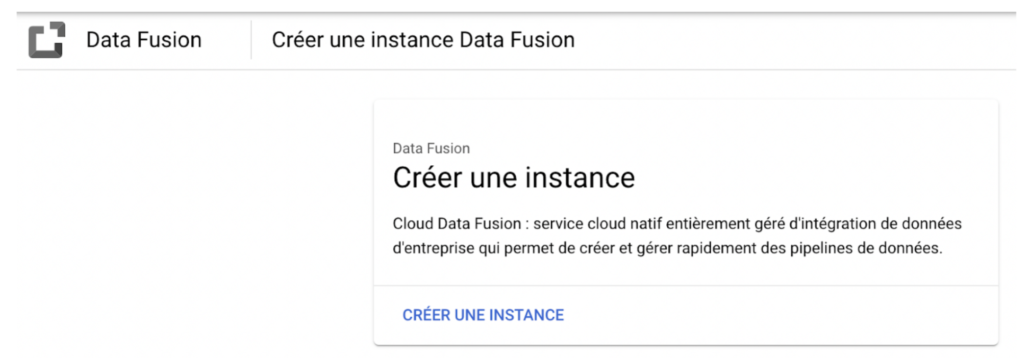
Autorisez Dataproc (cette étape n’est pas importante dans notre cas, mais il vaut mieux autoriser cet outil qui est complémentaire de Google Cloud Data Fusion dans le cas où vous devez travailler avec des ensembles de données (datasets) très volumineux). Dataproc est un service entièrement géré et hautement extensible (« scalable ») qui vous permet d’exécuter des outils d’analyse de données open-source (logiciels libres comme Apache Spark, Apache Flink, et Presto) pour moderniser des data lake (lacs de données) et ETL.
Allez tout en bas de la page pour créer votre instance. Notez que cela peut prendre un certain temps.

Dans le menu à gauche, cliquez sur Instances.
Vous devriez voir votre instance en train d’être créée.
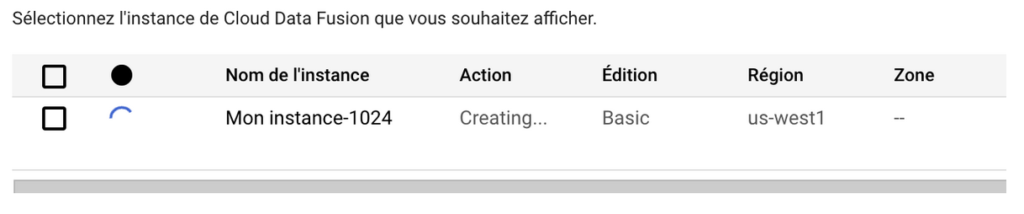
Une fois l’instance chargée, rendez-vous dessus en cliquant sur le nom de votre instance, puis en cliquant sur “View instance”.
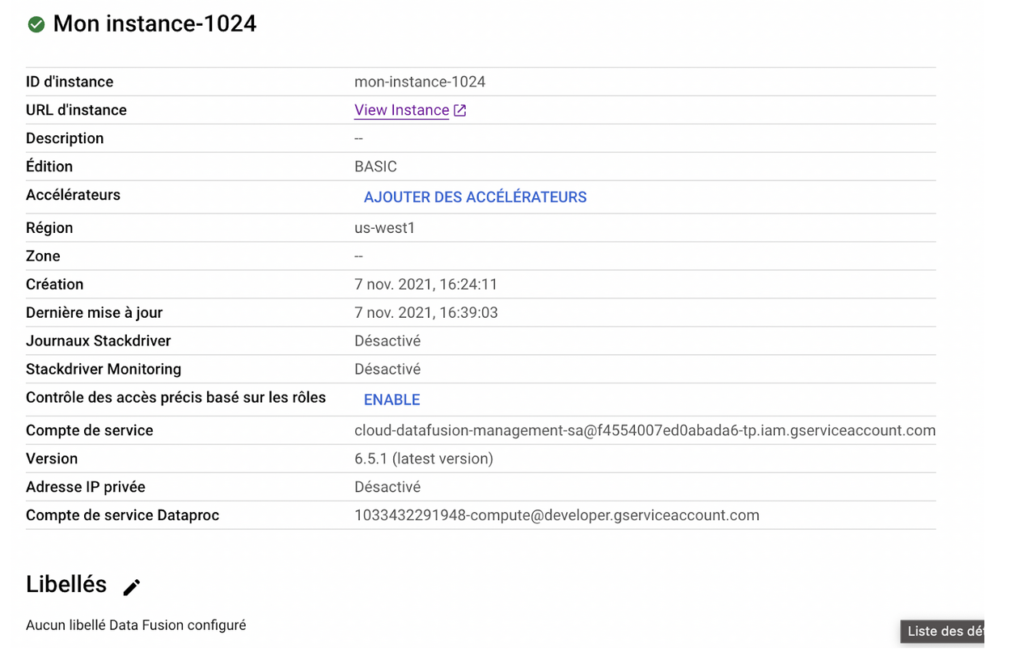
Création de l’ETL
Dans un premier temps, vous allez charger un fichier CSV dans votre instance (Extract), puis procéder à un certain nombre de transformations pour le rendre utilisable pour de l’analyse ou de la lecture de données.
Cliquez sur l’onglet “Wrangler”
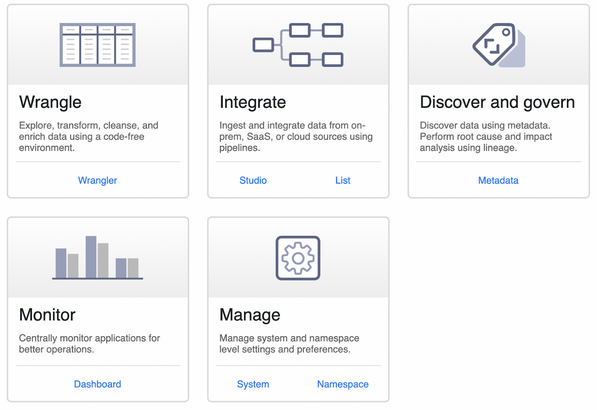
Afin de téléversez un fichier CSV ou Excel, présent sur votre ordinateur. Pour suivre à l’identique l’exemple de l’article, vous pouvez télécharger le fichier « ville-metric.csv » qui contient les données.
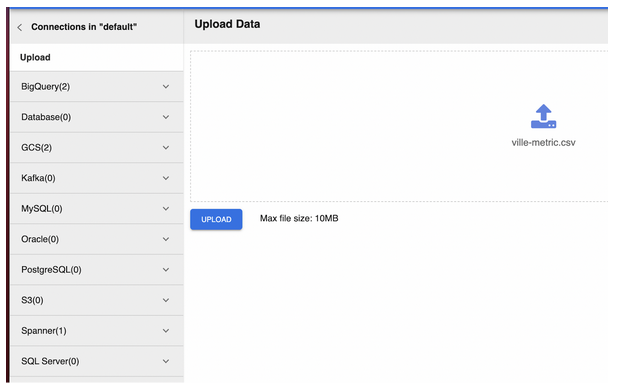
Cliquez sur le bouton UPLOAD pour téléverser le fichier “ville-metric.csv”. Vous aurez un aperçu des données du fichier.
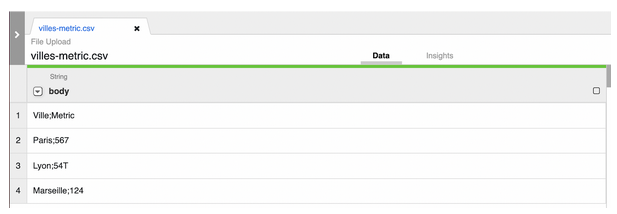
Il faut maintenant s’assurer que les données du fichier sont propres pour ne pas créer d’erreur lors de l’analyse de données. En effet, cette étape est primordiale pour réaliser une analyse de données juste. Si les données contiennent des erreurs ou ne sont pas correctement interrogées, les décisions ou les indices de performance qui s’appuient dessus seront naturellement impactés.
Cliquez sur la flèche à gauche de body, puis sélectionnez Parse → CSV. Sélectionnez “Custom delimiter” et entrez un point-virgule “;” dans la barre dédiée à cet effet, puis cliquez sur “”Set first row as header”, et enfin sur “Apply”.
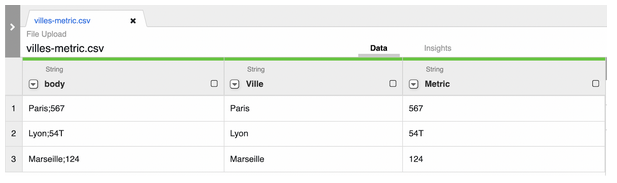
Vous données sont désormais regroupées par colonne, mais dans la colonne Metric, la ligne 2 contient une erreur puisqu’elle contient un “T” alors que seules les données numériques sont autorisées. Nous allons donc enlever ce caractère dans Cloud Data Fusion. Cliquez sur la flèche de la colonne Metric, puis sur “Find and replace”. L’outil Wrangler va itérer chaque ligne de la colonne Metric pour chercher la présence du caractère “T”, et dans ce cas l’effacer.
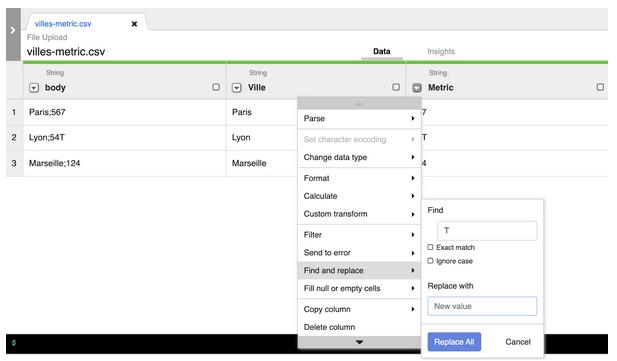
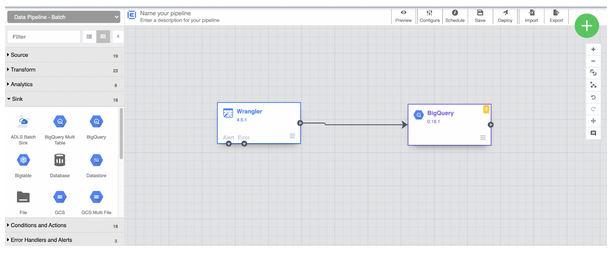
Vos données sont désormais prêtes à être chargées dans un pipeline (silo) de données en cliquant sur “Create a pipeline”. Cette épate permet de charger vos données dans un entrepôt de données (data warehouse) dédié, afin de les stocker et les analyser ultérieurement. L’outil phare pour ce besoin sur Google Cloud Platform n’est autre que BigQuery ! Pour lire nos articles sur le sujet, cliquez-ici.
Ici vous pouvez donc insérer un objet BigQuery qui recevra les données extraites et nettoyées dans votre instance Data Fusion.
Si vous avez besoin d’aide sur un sujet similaire, n’hésitez pas à prendre contact avec nous !
Félicitations !
Vous avez créé un processus ETL afin d’extraire des données pour les nettoyer et les charger dans une table BigQuery. Vos données sont désormais propres, et prêtes pour être analysées. Vos rapports et tableaux de bord peuvent désormais s’appuyer sans crainte sur ces données !
La charge de travail nécessaire pour mettre en place cet ETL n’est pas conséquente, et grâce à l’infrastructure Cloud de Data Fusion vous n’avez qu’à vous concentrer sur l’essentiel. Vous gagnez donc du temps en évitant d’écrire vous même les requêtes (query) SQL, et pour ceux sur un schéma Cloud hybride vous pouvez même profitez de plugins pour connecter vos données aux Cloud Amazon AWS et Microsoft Azure !
Besoin d'un peu plus d'aide sur Looker Studio ?
Des formateurs sont disponibles toute l'année pour vous accompagner et optimiser votre utilisation de Looker Studio, que ce soit pour votre entreprise ou pour vos besoins personnels !
Découvrir nos formations Looker Studio
- Articles connexes
- Plus de l'auteur






