
 Looker Studio
Looker Studio 
Pourquoi les bases de données NoSql ne sont pas adaptées à l’analyse de données
Il y a quelques années les problématiques Big Data ne pouvaient être adressées que par des solutions avec des bases de données* NoSql (BigTable, HBase, …), mais cette époque est révolue. Et comme vous l’aurez […]

Ce que vous allez découvrir
- Qu’est-ce qu’une base de données NoSql ?
- Mais alors quelles sont les limites?
- Quelle utilité pour les bases de données NoSql ?
Pourquoi les bases de données NoSql ne sont pas adaptées à l’analyse de données

Il y a quelques années les problématiques Big Data ne pouvaient être adressées que par des solutions avec des bases de données* NoSql (BigTable, HBase, …), mais cette époque est révolue. Et comme vous l’aurez compris, je ne conseille pas l’utilisation de ces outils pour l’analyse des données.
Les défenseurs des bases de données vont être nombreux à lever leur bouclier, mais dans cet article vous trouverez une argumentation qui démontre les limites de ces solutions. De plus, si Google a décidé de développer une base de données spécifiquement pour l’analyse des données Big Data (BigQuery), je ne pense pas faire totalement fausse route…
Qu’est-ce qu’une base de données NoSql ?
Les bases de données NoSql ont été créées pour répondre à la problématique de la volumétrie de données qui interdisait l’utilisation de base de données historiques à partir d’un certain point de rupture. En effet, quand on dépasse une certaine volumétrie il faut que le “moteur” de la base de données fonctionne sur plusieurs machines en même temps, on parle alors d’architecture distribuée. Le gain ici s’explique par la démultiplication de la puissance de calcul, plus on répartit la tâche sur un grand nombre de machines, plus le résultat sera atteint rapidement. Les bases de données historiques (Oracle, Sql Server, PostgreSQL, …) n’en sont pas capables (de part leur architecture mono-serveur) car c’est une problématique qui est simple à énoncer mais plus difficile à mettre en œuvre.
Pour régler ce problème, les bases de données NoSql proposent de découper les données selon une clé de répartition. Cette clé de répartition est centrale et c’est elle qui doit garantir la répartition des charges (données et calcul) entre les différentes machines. Les données sont physiquement séparées sur les machines donc si la clé est mal choisie les performances vont être catastrophiques voire même inférieures aux bases de données historiques.
Il faut également préciser que la base de données est constituée d’une seule table et il faut donc dé-normaliser les données, c’est-à-dire que chaque ligne de la base de données doit contenir la totalité des données (exemple : un article n’est pas référencé par un identifiant qui nous permettra de retrouver son nom, son code ou tout autre donnée relatif à cet article, mais le nom, le code et toutes les informations relatives à cet article sont contenus à chaque ligne de données). Ce mécanisme crée une redondance des données.
Prenons l’exemple des données commerciales d’une entreprise découpées selon l’axe des clients. Pour chaque client, nous trouvons des données qui lui sont attribuées : un nom, une adresse, un email, et surtout des commandes.
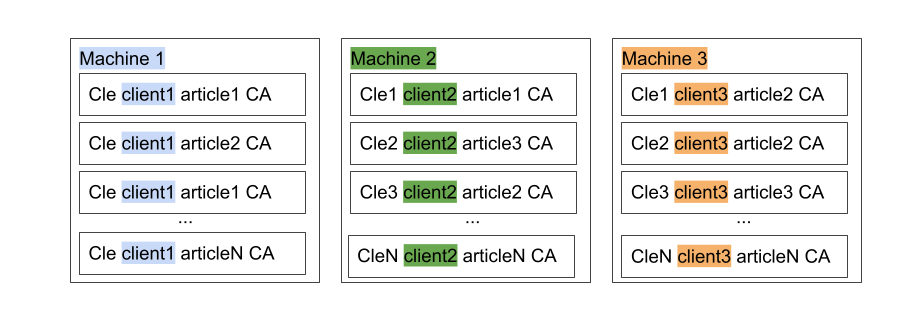
Cette base de données va être ultra-performante pour enregistrer un grand nombre de commandes provenant de multiples clients. En revanche si vous avez un gros client qui est responsable de la plupart de vos commandes cela ne fonctionnera pas bien voire pas du tout, car la plupart des opérations seront dirigées vers la même zone de données et dévolues à une seule machine. On ne profite pas de l’architecture répartie et donc on ne dispose pas d’assez de puissance pour traiter le volume des données en entrée.
De façon analogue si vous souhaitez faire la moyenne du chiffre d’affaires par client et par commande vous aurez des performances optimales car chaque machine dispose des informations adéquates et va travailler de manière autonome et en parallèle.
Mais alors quelles sont les limites?
Certains d’entre vous auront déjà compris que cette clé de répartition est un gros problème quand on parle d’analyse de données. En effet, quand on analyse les données on va essayer plusieurs axes d’analyse. Dans notre précédent exemple, si on souhaite faire la moyenne des commandes par article, les performances vont être catastrophiques car les données sont mélangées sur les différentes machines, il faut donc lire les données avant de partager les tâches aux différents processeurs.
De plus, il est très difficile de croiser les données entre plusieurs tables. Ces bases de données sont mono table et c’est la principale différence avec les autres bases de données dites relationnelles (je n’utilise pas le terme SQL, car le SQL n’est pas une technologie mais un standard de requête qui permet d’interroger de manière générique un grand nombre de bases de données). On peut toujours injecter les données des autres tables dans la base NoSql, mais cette méthode de contournement ne permet pas de régler toutes les problématiques (tous les croisements ne sont pas gérés par cette solution).
En outre, la dénormalisation est un problème, en effet si vous avez décidé de modifier le nom d’un article et qu’il se retrouve des milliards de fois dans votre base de données, la mise à jour peut faire chuter les performances, sans compter que votre base de données peut-être inconsistante pendant un certain temps (c’est à dire qu’un même article peut avoir deux noms différents en même temps).
On comprend bien que si on veut limiter les ressources à utiliser (une base de données pour chaque table principale plus des ressources pour traiter les agrégations non gérées par la clé de répartition), il faut séparer les données des processeurs et monter une architecture temporaire pour chaque requête.
C’est exactement ce que Google a fait avec Big Query qui est une base de données relationnelle Big Data et qui supporte le SQL car c’est un gage d’interopérabilité avec de nombreux outils (outils de reporting notamment).
Il faut noter également que dans le cadre de l’analyse de données, les bases de données non structurées ne sont pas un avantage mais sont même contre productives, car il faudra passer par une étape de normalisation avant l’analyse. En effet on ne peut pas agréger des données hétérogènes ou comparer ce qui n’est pas comparable (ajouter des surface avec des volumes n’a pas de sens).
Quelle utilité pour les bases de données NoSql ?
Avec l’avènement de solutions Big Data relationnelles (Big Query et Cloud Spanner pour ne pas les nommer), Google se désengage petit à petit des bases de données NoSql. La question légitime est de se demander si les bases de données NoSql ont de l’avenir.
Comme on a pu le voir précédemment, les bases NoSql sont ultra performantes dans de rares cas comme pour ingérer des millions de lignes de données par secondes. De plus, ces bases de données non structurées sont très adaptées à certaines applications, comme les sites de e-commerce par exemple, car elles permettent de stocker les différents articles en vente bien qu’ils aient des caractéristiques, des dimensions ou des propriétés différentes. Dans le cadre d’analyse de données (ma spécialité), elles peuvent être des points d’entrées et faire une première agrégation des données avant une analyse plus poussée lorsque la volumétrie est vraiment trop importante (cas extrêmement rares).
En fait, ces bases de données sont comme des Formules 1. Elles sont destinées à des besoins pointus mais restent onéreuses à mettre en œuvre, à maintenir et nécessitent des ressources ultra qualifiées.
Base de données*: Une base de données permet de stocker et de retrouver des données. C’est un outil essentiel pour une application ou dans le processus de l’analyse de données. Il existe 2 types principaux de base de données
- les bases de données relationnelles et structurées qui reposent sur des schémas normalisés de plusieurs tables dont le nombre de colonnes est fixe et dont les types sont définis.
- Les bases de données NoSql qui représente une seule table généralement non structurée (c’est à dire qu’un enregistrement n’a pas un nombre de champs fixe (le terme champ est préférable à celui de colonne du fait que la table n’est pas structurée). Ces bases de données reposent sur une architecture distribuée de plusieurs machines. Elles se sont développées sous l’impulsion des géants de l’informatique pour répondre à leurs besoins spécifiques. Il en existe de plusieurs types en fonction des besoins (comme MongoDB qui est conçu pour gérer les documents ou Neo4J pour gérer les graphes).
Besoin d'un peu plus d'aide sur Google Forms ?
Des formateurs sont disponibles toute l'année pour vous accompagner et optimiser votre utilisation de Google Forms, que ce soit pour votre entreprise ou pour vos besoins personnels !
Découvrir nos formations Google Forms
- Articles connexes
- Plus de l'auteur

News
Google Photos : le site Web commence à afficher la qualité de sauvegarde de chaque image
Les ajustements et les petits ajouts à Google Photos se poursuivent avec le volet d'informations sur le Web obtenant une section "sauvegardée" plutôt utile. Affichage de la qualité de sauvegarde ...
1 min
![]() Misa 3 ans
Misa 3 ans






