
 Looker Studio
Looker Studio 
Google Sheets : traiter, utiliser, partager les données efficacement : 1/5 – construire des tables de données avec Google Sheets
Avant-propos Google Sheets est souvent utilisé en entreprise pour réaliser des tableaux de bord qui répondent à un besoin précis. Je veux un tableau des ventes de plusieurs produits sur l’année. L’utilisateur construit directement le […]

Ce que vous allez découvrir
- Avant-propos
- Système d'information
- Une base de données, c'est quoi ?
- Une feuille par table, une table par feuille
- Une seule entrée dans les colonnes svp !
- Une ligne est un individu : unique et identifiable.
- Qu'est-ce qui détermine qu'un ensemble de données doit faire l'objet d'une table propre ?
Google Sheets : traiter, utiliser, partager les données efficacement : 1/5 – construire des tables de données avec Google Sheets

Avant-propos
Google Sheets est souvent utilisé en entreprise pour réaliser des tableaux de bord qui répondent à un besoin précis.
Je veux un tableau des ventes de plusieurs produits sur l’année.
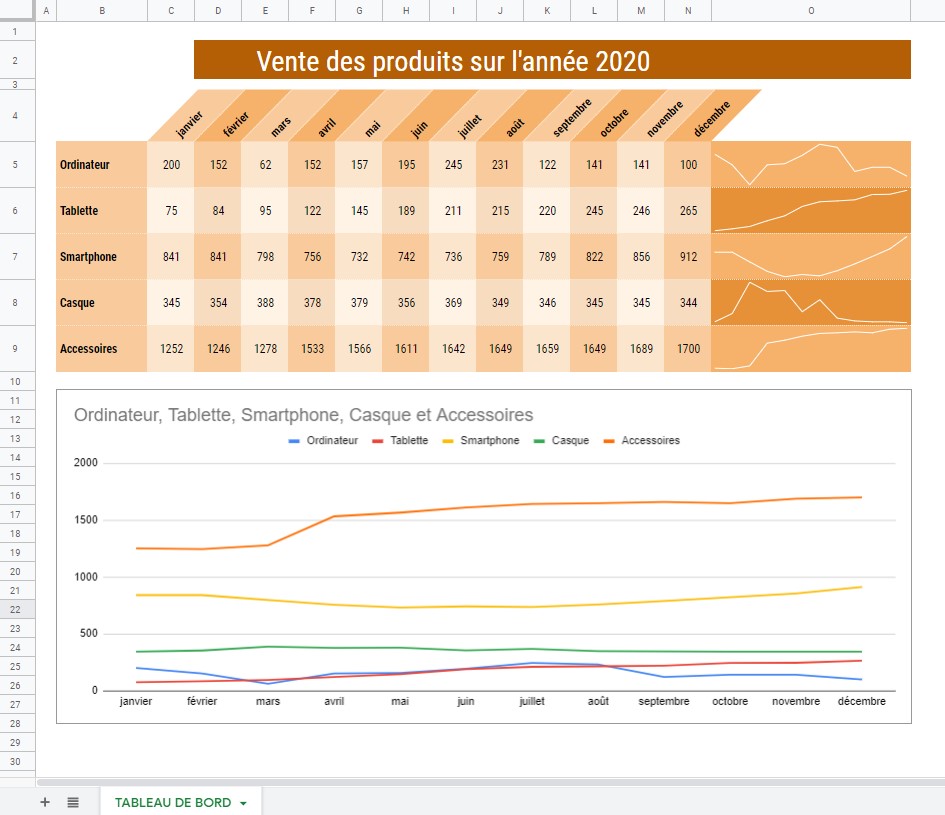
L’utilisateur construit directement le résultat final qu’il attend, avec de jolies couleurs, des croisements d’informations, des graphiques, des lignes regroupées par année ou par types de produits… Et c’est bien normal ! Quelle satisfaction de voir directement la concrétisation de son besoin.
Si le besoin initial est atteint dans cet exemple, d’autres besoins secondaires surgiront forcément : connaître le chiffre d’affaires de chaque produit en fonction du prix de vente réel, ou encore afficher une répartition par marque de produits, etc.
Et quid de la mise à jour des données qui viendront perturber la jolie mise en page ? Quid du partage de l’information avec d’autres personnes ou d’autres services ? Quid de l’exploitation de ces données dans un Google Agenda ou un Google Docs ?
Ce questionnement sur la circulation des données et l’automatisation de tâches implique de considérer Google Sheets comme un véritable système d’information, au même titre qu’un ERP (Enterprise Ressource Planning) ou d’un CRM (Customer Relationship Management) ou encore d’une GED (Gestion Electronique des Documents) ou encore de CMS (Content Management System)…
Utiliser Google Sheets pour créer un système d’information efficace requiert de différencier :
- Le traitement des données (recueil, ajout, modification) dans une base de données structurée et exploitable ;
- L’utilisation des données (affichage, analyse, production… dans des vues, des tableaux de bord, des graphiques, des applications tierces etc.)
L’objectif de cet article est de sensibiliser aux notions essentielles de structuration d’une base de données dans le cadre d’un véritable protocole (SQL) et de mettre ces notions en application dans la construction de tables des données sur Google Sheets. Il ne requiert pas de compétences techniques particulières, il propose une approche globale et, à mon sens, efficiente de l’utilisation de Google Sheets.
Système d’information
Un système d’information est un programme qui généralement exploite une base de données pour créer des affichages compréhensibles par un humain grâce à un ensemble de fonctions.
Cette architecture s’appelle MVC (Modèle – Vue – Contrôleur).
(PS : Le terme « Modèle » était source de confusion pour moi, il désigne la base de données, et non un template ou un exemple. Et perso j’aurai mis « Vue » à la fin car à mon sens c’est le résultat final. Je préfère le terme Data – Contrôleur – Vue.)
Par exemple, la page du site Internet que vous êtes en train de consulter est une vue au format HTML compilant des informations récupérées grâce à des requêtes et utilisées par à un moteur de création.
Le système d’information qui génère cette page est WordPress, le CMS (Content Management System) mondialement connu.
Une base de données, c’est quoi ?
Définition :
Une base de données (data base) est un ensemble d’informations organisées par tables de données. Une base est donc constituée de plusieurs tables.
DemOwa
WordPress par exemple exploite de nombreuses tables de données pour fabriquer la page du site. Il y a une table « articles » qui contient a minima : le titre de l’article, la date de publication, l’auteur… puis une table « blocs » rassemblant les différents éléments de cette page, une table « auteurs » qui contient le prénom, nom, description de l’auteur affichés en bas de page etc.
Les bases de données sont gérées par des langages spécifiques. Dans le cas de WordPress, il s’agit de SQL. Voici à quoi ressemble une plateforme d’administration des bases de données SQL.
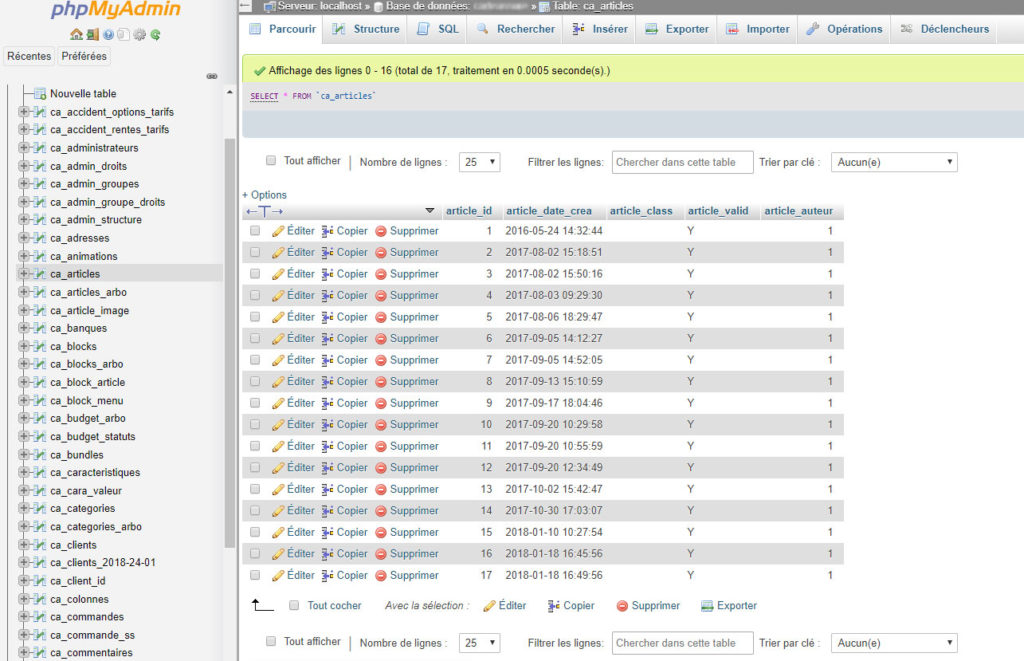
Google Sheets n’a pas pour ambition de suppléer SQL. Pour autant, voici quelques recommandations pour utiliser au mieux l’environnement Sheets afin d’organiser les informations comme dans une vraie base de données.
Une feuille par table, une table par feuille
Sous Sheets je conseille de créer une feuille de calcul pour chaque table de données. Plusieurs tables peuvent être sur le même SpreadSheets, et la base de données peut rassembler plusieurs SpreadSheets.
Point vocabulaire : dans cet article je ferai la distinction entre « Base de données » et « Table de données » : une base de données est un ensemble de tables de données.
Voyons en détail comment construire une table :
Une seule entrée dans les colonnes svp !
Une table de données est un tableau à une seule entrée : les colonnes représentent les « champs ». Chaque champ est une information qui caractérise les données. Prenons par exemple une table de données CLIENTS :
| Civilité | Prénom | Nom | Date d’entrée | Téléphone | |
La table est construite sous la forme d’un tableau à une seule entrée par colonnes. Chaque colonne doit avoir un titre, pas de syntaxe particulière ici, contrairement à SQL qui refuse tout accent ou caractères spéciaux.
Chaque colonne doit avoir un format précis parmi :
- Texte (ou chaîne de caractères ou VarChar en BDD) ;
- Nombre ;
- Booléenne (VRAI ou FAUX) ;
- Date.
Avec SQL il faut définir très précisément le type de données : si c’est une chaîne de caractères, combien de caractères maximum ? Quel format de nombres, entre quelle et quelle valeurs, est-ce un nombre décimal, avec quelle précision ? etc. Aucune donnée hors format ne peut être saisie sous peine d’erreur fatale (Fatal Error) ! Ce qui est très contraignant, mais indispensable à une bonne optimisation de la table.
Sheets est moins strict (car rappelons-le le rôle d’organisateur des données n’est pas sa priorité), ce qui implique qu’il faut anticiper l’utilisation de la donnée pour choisir le meilleur format et respecter ensuite ce format. Donc, par exemple, si la colonne attend un nombre, il ne faut pas écrire : « entre 5 et 10 ». :).
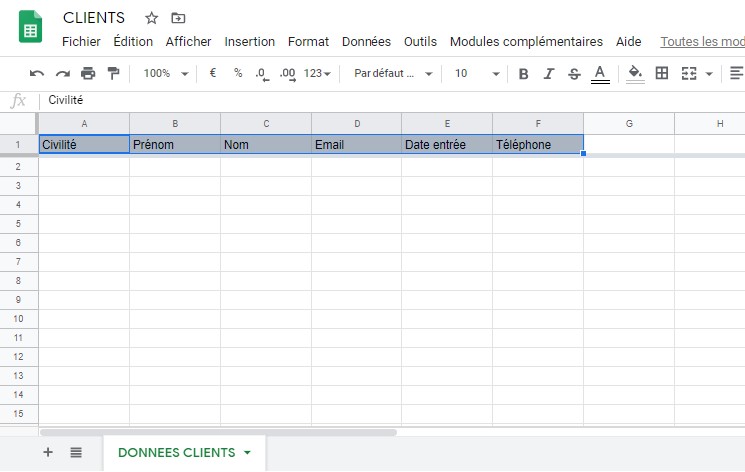
TP : Créer la table de données « CLIENTS »

- Créez un SpreadSheet « CLIENTS » puis une feuille « DONNÉES CLIENTS » ;
- figez la première ligne (aucune obligation, mais bien pratique pour la lisibilité) ;
- nommez les différentes colonnes : Civilité, Prénom, Nom, E-mail, Date d’entrée, téléphone
- appliquez un format couleurs alternées pour la lisibilité.
Points de vigilance :
- Pas de cellules fusionnées ou de doubles lignes de titres ;
- pas de titre de feuille dans la feuille ;
- pas de lignes ou colonnes vides « pour aérer » pour faire des marges ;
- pas de chichi, pas de Blabla.
Une ligne est un individu : unique et identifiable.
Chaque ligne (appelée « entrée » en SQL) représente un individu de la table. Il faut une ligne par individu et un individu par ligne.
Il est essentiel d’identifier chaque ligne à l’aide d’un code normalisé : une référence unique, comme un numéro de sécurité social, qui permettra de repérer la ligne et donc l’individu plus tard.
Pour faire court nous emploierons le terme « ID » (prononcer « AieDi » 🙂 )

Ajoutez donc systématiquement une colonne « ID » au début de votre table de données. au début par habitude et pour montrer l’importance de cette information.
SQL crée automatiquement un ID, sous forme numérique à chaque création de ligne (auto-incrémentation). Cet ID est aussi nommée « Clef » (Key) et jouera un rôle essentiel dans l’exploitation et la mise en relation des données.
Sur Sheets, je préconise de former les ID avec un groupe de deux ou trois lettres identifiant la table, puis un nombre à trois ou quatre chiffres qui devrait s’incrémenter à chaque création de ligne (tâche automatisable avec un petit script). Donc mes « clients » de la table « DONNEES CLIENTS » auront un ID sous la forme CL-0000. J’envisage pour l’instant de lister 999 clients. Au 1000ème , j’ouvrirai le champagne et passerai sur cinq chiffres, pas de souci.
TP : Ajoutez une première colonne « ID CLIENT », créez l’ID « CL-001 » puis étirez la cellule pour créer les 100 premiers IDs de votre table. remplissez les premières lignes :
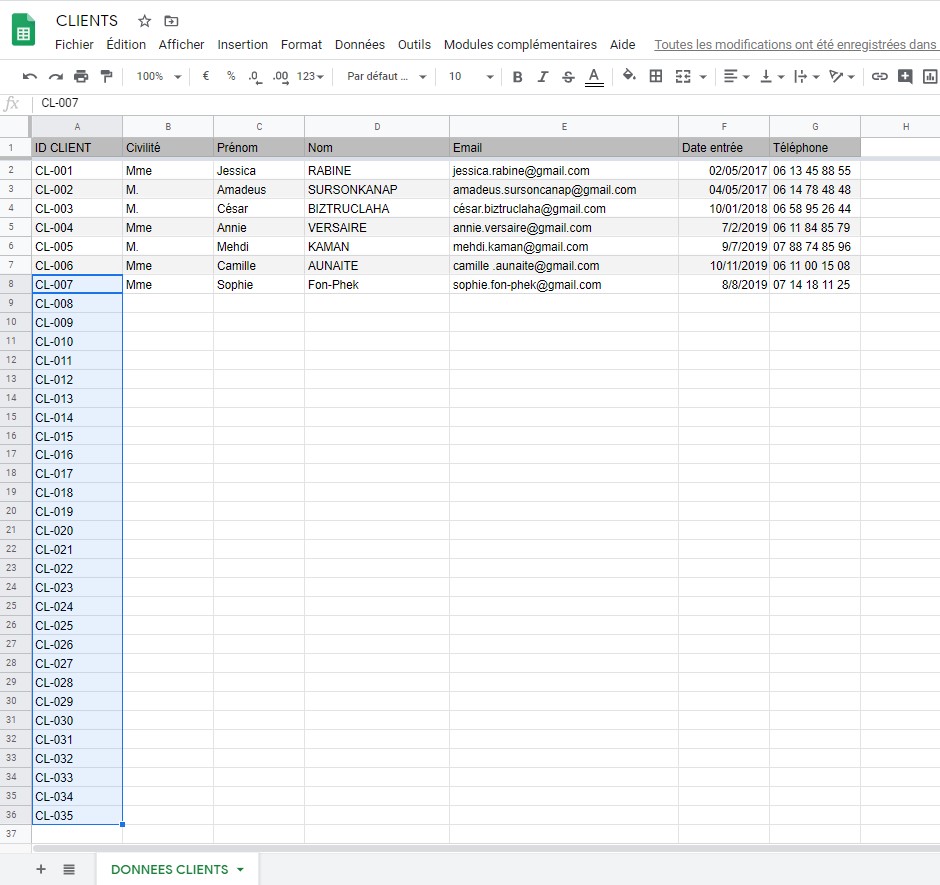
Points de vigilance :
- Attribuer un seul ID au même individu ;
- attribuer un seul individu à un ID ;
- en cas de suppression d’une ligne, ne pas réattribuer l’ID à un nouvel individu ;
- ne pas changer l’ID d’un individu !
- pas de fusion de cellule ;
- pas de groupement ou titres de groupement !
Qu’est-ce qui détermine qu’un ensemble de données doit faire l’objet d’une table propre ?
Il arrive que de nouvelles informations doivent être gérées par l’organisation. La question que vous devez vous poser est de savoir si cette nouvelle information peut se satisfaire d’une ou plusieurs colonnes d’une table existante ou bien si elle mérite une table de données dédiée.
TP : Marie-Sophie de la gestion client vous informe que les clients ont deux numéros de téléphone.
Renommez la colonne « Téléphone » en « Téléphone 1 » et ajoutez une colonne « Téléphone 2 »:
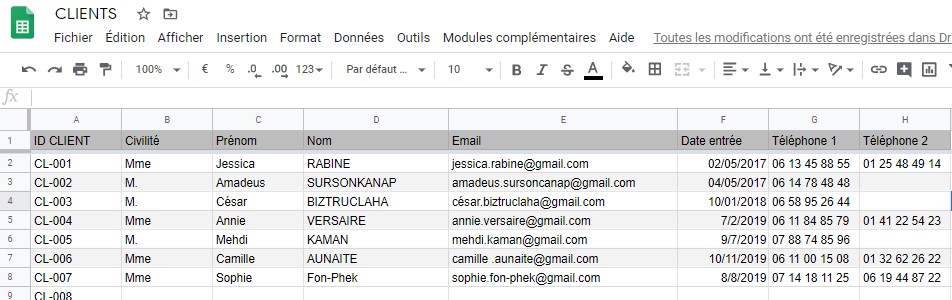
A priori nous ne devrions pas avoir besoin d’un troisième numéro de téléphone. Cette solution peut convenir.
TP : A présent, Régis de la compta a besoin de répertorier l’adresse postale de facturation pour chaque client.
Ajoutez une série de colonnes à notre table de données « Adresse ligne 1 », « Adresse ligne 2 », « Code postal », « Ville », « Pays » :

TP : Ursulla du service expédition a besoin de, je cite « au moins deux adresses de livraison ».
L’ajout de plusieurs groupes de cinq colonnes (avec l’information « Facturation », « Livraison 1 », « Livraison 2 » en plus dans le titre de chaque colonne) va rapidement s’avérer laborieuse et consommateur de place… et tiens, il faut dix nouvelles adresses de livraison pour un client (un grand-père qui envoie des cadeaux à chacun de ses petits-enfants:) ).
La solution d’ajouter cinq colonnes par adresse n’est plus gérable.
Il est temps pour cette accumulation d’informations de créer une nouvelle table de données « ADRESSES ».
TP : Créer la table de données des adresses postales des clients.
Ouvrez dans le même SpreadSheets une feuille de calcul « DONNEES ADRESSES ».
- première colonne : « ID ADRESSE », je vous propose le nommage AD-000 ;
- deuxième colonne : « CLIENT », pour indiquer à qui appartient l’adresse (appliquez une validation des données dans cette colonne qui permet de choisir parmi les ID CLIENTS disponibles) ;
- colonnes suivantes : les informations postales classiques (adresse ligne 1, adresse ligne 2, code postal, ville, Pays) ;
- ajoutons une nouvelle colonne « Type », pour caractériser l’adresse (« Facturation » ou « Livraison » ?) ;
- … libre à vous d’imaginer d’autres champs… interphone ? étage ? informations pour le livreur ?…
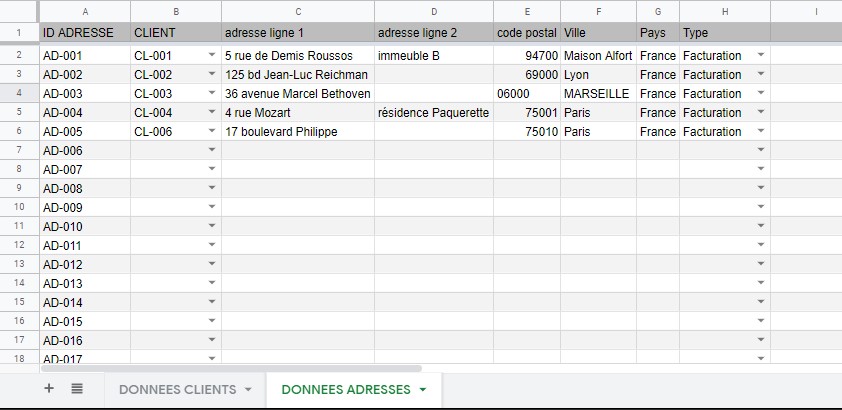
Les adresses sont stockées dans une table de données dédiée. Le champ client stocke l’ID CLIENT qui permet de créer la première relation entre les deux tables.
Ce premier article avait pour objectif d’identifier les caractéristiques techniques d’une table de données.
Dans l’article suivant (en cours), nous verrons comment mettre en relation ces tables, afin de récupérer des informations d’une table dans une autre par exemple.
Besoin d'un peu plus d'aide sur Sheets ?
Des formateurs sont disponibles toute l'année pour vous accompagner et optimiser votre utilisation de Sheets, que ce soit pour votre entreprise ou pour vos besoins personnels !
Découvrir nos formations Sheets
- Articles connexes
- Plus de l'auteur



News
Comment GSuite aide les entreprises et les écoles à rester connectés face au coronavirus
Javier Soltero, Directeur général et vice-président de G Suite, en pleine épidémie du CORONAVIRUS dans le monde a annoncé ce 3/3/2020, quelques mesures de Google pour aider les écoles et ...
2 min
![]() Thierry Vanoffe 6 ans
Thierry Vanoffe 6 ans

Google Sheets : traiter, utiliser, partager les données efficacement : 3/5 – créer, modifier, mettre à jour une entrée dans ...
Les deux premiers articles de cette série traitaient de la structure d'une table de données et de la mise en relation des tables entre elles. Abordons dans ce nouvel article ...
4 min
![]() Antoine MARTIN 5 ans
Antoine MARTIN 5 ans



Consultant et formateur sur les outils bureautiques, j'ai intégré l'équipe de Numericoach en 2020. J'accompagne les utilisateurs de Google Workspace à trouver des solutions répondant à leurs besoins. Mes domaines de prédilections sont les outils Sheets, Docs, Slides et Google Apps Script.











Top ! merci Martin pour ces éclairages ! J’ai hâte de connaitre la suite !
Yes, ça arrive 🙂
Excellent article dont tu as secret Antoine ! Good game, vivement la suite 😉
Merci Thierry ! La suite arrive dans la semaine 🙂
« Une feuille par table, une table par feuille »
« Une seule entrée dans les colonnes svp ! »
J’adore !
Merci
🙂
Merci pour votre article, cela m’aide beaucoup.
Néanmoins, dans le TP « Créer la table d’adresses… » vous proposer de créer une colonne « type » pour y caractériser l’adresse (facturation / livraison…).
Je ne comprends pas comment créer une liste de « caractérisation d’adresse ».
Avez-vous un article dédié à ce sujet?
Merci
Bonjour, vous pouvez par exemple créer une autre feuille et lister tous les types d’adresse que vous souhaitez référencer.
type adresse
facturation
devis
livraison
Dans la base de données, affichez cette liste en utilisant la validation de données et en vous servant de cette liste pour la validation.
Est-ce que cela répond à votre demande ?
Bonjour -:)
Ou la la. PAS D’ACCORD MESSIEURS ! ! ! ,
Effectivement, à contrario d’une feuille Excel, avec Google Sheets on peut enfin partager des feuilles de calcul à plusieurs sur le net , sur un espace relativement sécurisé et donner l’illusion que l’on peut mettre en place une application qui peut à moindre coûts se substituer à une appli assez chère, écrite d’une manière traditionnelle reliée à un SGBD.
En effet il est cool de penser qu’à moindre effort (mode du « No Code ») on va développer une appli multi-user en toute simplicité sans se casser la tête et en un temps record. L’idée est séduisante, elle n’est pas nouvelle, et elle me séduit moi aussi . Depuis que les tableurs et les SGBD existent, j’ai souvent eu l’occasion d’en débattre. Bien qu’à l’époque les bidouilleurs bureautique reliaient pour cela leurs applis avec des SGBD via des passerelles comme ODBC par exemple et ça fonctionnait plutôt bien puisqu’ils utilisaient le moteur de la base de données pour assurer toute les fonctions sécuritaires, avec les verrous nécessaires pour garder la COHERENCE des données.
Aujourd’hui faire des formules de tableur pour établir cette cohérence est en effet possible, mais ultra casse gueule et très difficile à sécuriser, surtout vis à vis des erreurs des utilisateurs (certains plus ou moins avisés d’où danger). C’est en fait, une apparente simplicité, mais à la fin on aura de tt façon passé bcp de temps, pour un résultat peu sécure et peu professionnel.
Un ensemble de feuilles de calcul ne peuvent se substituer à un SGBD … Le faire reste illusoire et ultra-fragile à maintenir, ça c’est de l’informatique de bidouilleur bureautique . . . Il manque un très grand nombre de fonctionnalités sécuritaires, de cohérence et de protection des données ( regarder les propriétés ACID).
Ces nouvelles capacités de partage de données ouvrent une boite de pandore, avec des effets bien mal maitrisables . Les règles d’unicité multi-tables artificiellement effectuées par des formules ou des macros ou autres fonctions cherchent à se substituer à un moteur de SGBD, mais elles ne sont pas reliés à la notion de transaction, et ça il me semble que c’est très très casse gueule. Bien sûr avec les VUES FILTREES ou les QUERY de Google Sheets, on a une fonction de type SELECT aussi puissante que celle de SQL et on est tenté de dire que ça y est ! , on y est !
Hélas non, il manque l’essentiel : la notion de VERROU , la notion de TRANSACTION c.a.d. (commit/ rollback) , et de journaux de transaction pour valider un ensemble d’opérations sur les tables.
Ainsi les opérations : CREATE, UPDATE, DELETE sont absents du langage de requête donc non sécurisés par un moteur de Base De Données et seront à votre entière charge de développement et de sécurisation. Ainsi il y a une complète dépendance entre les données et leur utilisation par l’application développée. Pour faire joujou, ça peut le faire. Pour monter une application un tant soit peu sérieuse. NON! En tout cas pour l’instant.
Derrière Google Sheets et ses tables est reliée à une énorme « Big Data » , une vraie base de donnée « king size » , avec tout ce qu’il faut. Mais pour l’instant Google n’autorise pas le « pecus » moyen à y mettre les doigts. Mais il paraît que c’est en projet. Et tout ça sera mis à disposition sans se prendre la tête avec de l’admin système ou de l’admin SGBD pour la gestion des index etc …
Je vous souhaite tous, bonne route, même si je pense que, honnêtement vous êtes dans l’erreur.
Bien Cordialement ,
Eric
Ingénieur Informaticien depuis 30 ans (DBA sur Ingres, MySQL, PostgreSQL) / Admin UNIX, LINUX. Infirmier et technicien du sommeil (aujourd’hui Resp. Informatique, pour une Société de sommeil)
Bonjour Eric,
Merci pour votre retour ! Vous dites ne pas être d’accord mais avec quoi exactement ?
En vous lisant je pense au contraire que l’on partage le même avis. En aucun cas je pense que les outils Google de base ne peuvent suppléer les outils de développement professionnels. L’article a uniquement pour objectif de sensibiliser les utilisateurs à la construction d’une table de données exploitable avec Sheets.
Bonne journée !